
01
Built for the hard questions.
It connects facts across many sources to answer the multi-hop questions a single search can't.
MothRag is built for the hard questions — the ones whose answer is spread across many documents, where ordinary AI search misses it. It connects the evidence and shows the reasoning behind every answer — deterministically, so the same question gives the same answer every time, not a different roll of the dice. New information is added just by embedding it — there's no knowledge graph to rebuild — so it stays accurate on data that changes every day. And it runs entirely on the LLM APIs you already pay for: no GPUs, no model hosting, no lock-in.
Most AI search does a single lookup and stops. That breaks the moment a question spans multiple documents, chains entities, or compares facts across sources — exactly the questions that matter most in real knowledge work. MothRag is built for that case, and ships as a Python package you point at any LLM API you already use.
It connects facts across many sources to answer the multi-hop questions a single search can't.
No GPUs to rent, no models to host, no special infrastructure — it runs on the standard LLM APIs you already use.
Every answer comes with the evidence and the reasoning trail behind it — so you can check it, not just trust it. The difference between a demo and something you can put in front of customers.
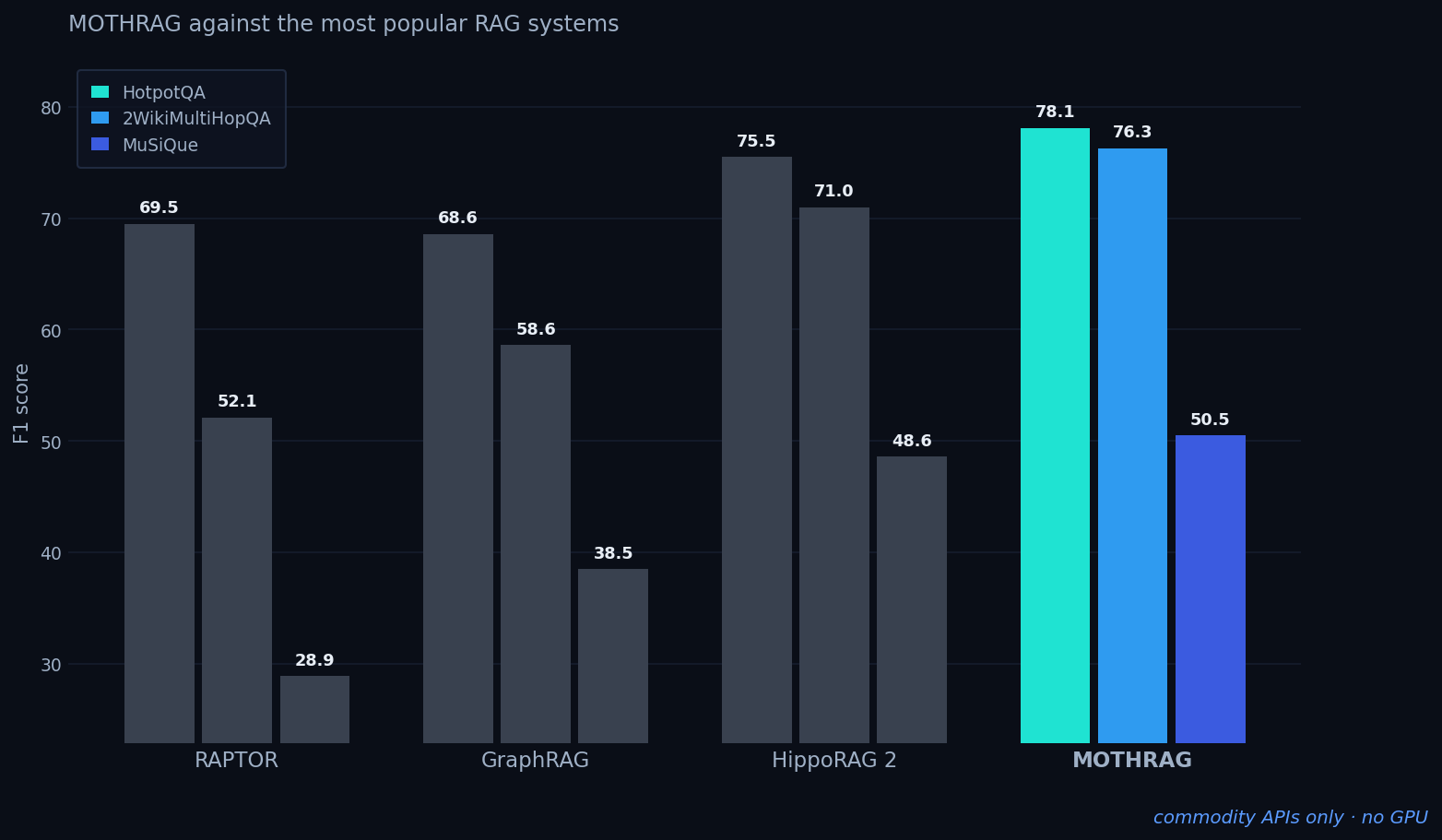
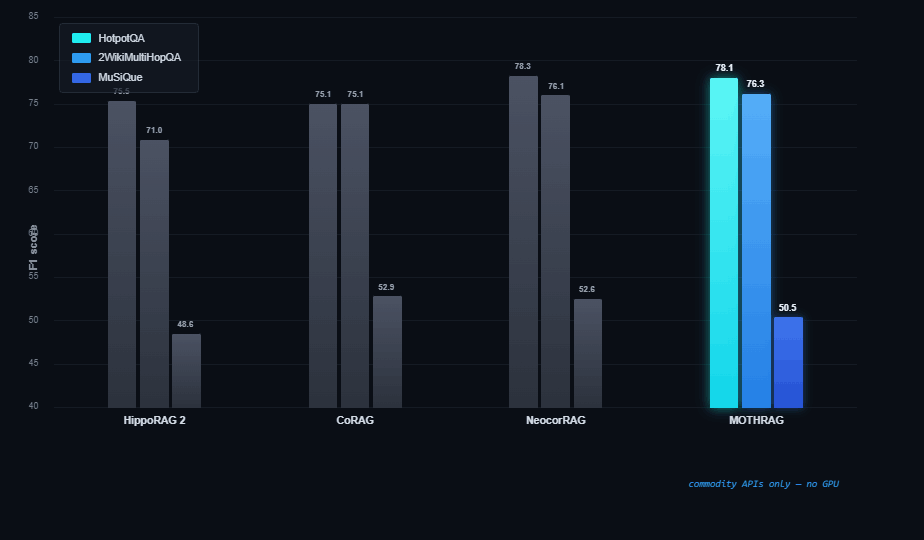
On the standard multi-hop benchmarks, MothRag beats the graph-based systems (HippoRAG, GraphRAG) outright and matches the best published research overall. The difference: the systems at this level need datacenter GPUs or non-commercial models — MothRag reaches it on commodity APIs alone.
No GPU fleet, no hosted models, no special infrastructure — MothRag runs entirely on the standard LLM APIs you already pay for.
Works with any model, today's or tomorrow's. Swap the engine underneath without retraining anything.
Every answer is structured as an inspectable reasoning trail over the evidence it used, with a built-in agreement signal across its internal reasoning paths — so you can gauge confidence at a glance.
New information is added just by embedding it — there's no knowledge graph to rebuild and nothing to retrain. Graph- and training-based systems re-index every time the data moves; MothRag doesn't.
Validated across three standard multi-hop benchmarks at the same scale researchers use (1000 evaluations each, Llama-3.3-70B reader): on par with the published research frontier — while running entirely on the standard LLM APIs you already use. Full numbers and methodology in the published paper.
MothRag is open source on GitHub and installable from PyPI with pip install mothrag. It ships a one-command CLI: run mothrag demo for an instant multi-hop answer over a bundled corpus, then point mothrag query at your own documents. The paper documenting the method and results is published on Zenodo.